Java ConcurrentMap
The Java programming language's Java Collections Framework version 1.5 and later defines and implements the original regular single-threaded Maps, and
also new thread-safe Maps implementing the java.util.ConcurrentMapinterface among other concurrent interfaces.
In Java 1.6, the java.util.NavigableMap interface was added, extending java.util.SortedMap,
and the java.util.ConcurrentNavigableMap interface was added as a subinterface combination.
Java Map Interfaces
The version 1.8 Map interface diagram has the shape below. Sets can be considered sub-cases of corresponding Maps in which the values are always a particular constant which can be ignored, although the Set API uses corresponding but differently named methods. At the bottom is the java.util.concurrent.ConcurrentNavigableMap, which is a multiple-inheritance.
Implementations
ConcurrentHashMap
For unordered access as defined in the java.util.Map interface, the java.util.concurrent.ConcurrentHashMap implements java.util.concurrent.ConcurrentMap. The mechanism is a hash access to a hash table with lists of entries, each entry holding a key, a value, the hash, and a next reference. Previous to Java 8, there were multiple locks each serializing access to a 'segment' of the table. In Java 8, native synchronization is used on the heads of the lists themselves, and the lists can mutate into small trees when they threaten to grow too large due to unfortunate hash collisions. Also, Java 8 uses the compare-and-set primitive optimistically to place the initial heads in the table, which is very fast. Performance is O(n) but there are delays occasionally when rehashing is necessary. After the hash table expands, it never shrinks, possibly leading to a memory 'leak' after entries are removed.
ConcurrentSkipListMap
For ordered access as defined by the java.util.NavigableMap interface, java.util.concurrent.ConcurrentSkipListMap was added in Java 1.6, and implements java.util.concurrent.ConcurrentMap and also java.util.concurrent.ConcurrentNavigableMap. It is a Skip list which uses Lock-free techniques to make a tree. Performance is O(log(n)).
Ctrie
- Ctrie A trie-based Lock-free tree.
AirConcurrentMap
- AirConcurrentMap Suitable for medium to large Maps. Parallel scan.
Concurrent modification problem
One problem solved by the Java 1.5 java.util.concurrent package is that of concurrent modification. The collection classes it provides may be reliably used by multiple Threads.
All Thread-shared non-concurrent Maps and other collections need to use some form of explicit locking such as native synchronization in order to prevent concurrent modification, or else there must be a way to prove from the program logic that concurrent modification cannot occur. Concurrent modification of a Map by multiple Threads will sometimes destroy the internal consistency of the data structures inside the Map, leading to bugs which manifest rarely or unpredictably, and which are difficult to detect and fix. Also, concurrent modification by one Thread with read access by another Thread or Threads will sometimes give unpredictable results to the reader, although the Map's internal consistency will not be destroyed. Using external program logic to prevent concurrent modification increases code complexity and creates an unpredictable risk of errors in existing and future code, although it enables non-concurrent Collections to be used. However, either locks or program logic cannot coordinate external threads which may come in contact with the Collection.
Modification counters
In order to help with the concurrent modification problem, the non-concurrent Map implementations and other Collections use internal modification counters which are consulted before and after a read to watch for changes: the writers increment the modification counters. A concurrent modification is supposed to be detected by this mechanism, throwing a java.util.ConcurrentModificationException, but it is not guaranteed to occur in all cases and should not be relied on. The counter maintenance is also a performance reducer. For performance reasons, the counters are not volatile, so it is not guaranteed that changes to them will be propagated between Threads.
Collections.synchronizedMap()
One solution to the concurrent modification problem is using a particular wrapper class provided by a factory in Collections: public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) which wraps an existing non-thread-safe Map with methods that synchronize on an internal mutex. There are also wrappers for the other kinds of Collections. This is a partial solution, because it is still possible that the underlying Map can be accessed inadvertently by Threads which keep or obtain unwrapped references. Also, all Collections implement the java.lang.Iterable but the synchronized-wrapped Maps and other wrapped Collections do not provide synchronized iterators, so the synchronization is left to the client code, which is slow and error prone and not possible to expect to be duplicated by other consumers of the synchronized Map. The entire duration of the iteration must be protected as well. Furthermore, a Map which is wrapped twice in different places will have different internal mutex Objects on which the synchronizations operate, allowing overlap. The delegation is a performance reducer, but modern Just-in-Time compilers often inline heavily, limiting the performance reduction. Here is how the wrapping works inside the wrapper - the mutex is just a final Object and m is the final wrapped Map:
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
The synchronization of the Iteration is recommended as follows, however, this synchronizes on the wrapper rather than on the internal mutex, allowing overlap:[1]
Map<String, String> wrappedMap = Collections.synchronizedMap(map);
...
synchronized (wrappedMap) {
for (String s : wrappedMap.keySet()) {
// some possibly long operation executed possibly
// many times, delaying all other accesses
}
}
Native synchronization
Any Map can be used safely in a multi-threaded system by ensuring that all accesses to it are handled by the Java synchronization mechanism:
Map<String, String> map = new HashMap<String, String>();
...
// Thread A
// Use the map itself as the lock. Any agreed object can be used instead.
synchronized(map) {
map.put("key","value");
}
..
// Thread B
synchronized (map) {
String result = map.get("key");
...
}
...
// Thread C
synchronized (map) {
for (Entry<String, String> s : map.entrySet()) {
/*
* Some possibly slow operation, delaying all other supposedly fast operations.
* Synchronization on individual iterations is not possible.
*/
...
}
}
ReentrantReadWriteLock
The code using a java.util.concurrent.ReentrantReadWriteLock is similar to that for native synchronization. However, for safety, the locks should be used in a try/finally block so that early exit such as Exception throwing or break/continue will be sure to pass through the unlock. This technique is better than using synchronization because reads can overlap each other, there is a new issue in deciding how to prioritize the writes with respect to the reads. For simplicity a java.util.concurrent.ReentrantLock can be used instead, which makes no read/write distinction. More operations on the locks are possible than with synchronization, such as tryLock() and tryLock(long timeout, TimeUnit unit).
final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
final ReadLock readLock = lock.readLock();
final WriteLock writeLock = lock.writeLock();
..
// Thread A
try {
writeLock.lock();
map.put("key","value");
...
} finally {
writeLock.unlock();
}
...
// Thread B
try {
readLock.lock();
String s = map.get("key");
..
} finally {
readLock.unlock();
}
// Thread C
try {
readLock.lock();
for (Entry<String, String> s : map.entrySet()) {
/*
* Some possibly slow operation, delaying all other supposedly fast operations.
* Synchronization on individual iterations is not possible.
*/
...
}
} finally {
readLock.unlock();
}
Convoys
Mutual exclusion has a Lock convoy problem, in which threads may pile up on a lock, causing the JVM to need to maintain expensive queues of waiters and to 'park' the waiting threads. It is expensive to park and unpark a thread, and a slow context switch may occur. Context switches require from microseconds to milliseconds, while the Map's own basic operations normally take nanoseconds. Performance can drop to a small fraction of a single Threads' throughput as contention increases. When there is no or little contention for the lock, there is little performance impact, however, except for the lock's contention test. Modern JVMs will inline most of the lock code, reducing it to only a few instructions, keeping the no-contention case very fast. Reentrant techniques like native synchronization or java.util.concurrent.ReentrantReadWriteLock however have extra performance-reducing baggage in the maintenance of the reentrancy depth, affecting the no-contention case as well. The Convoy problem seems to be easing with modern JVMS, but it can be hidden by slow context switching: in this case, latency will increase, but throughput will continue to be acceptable. With hundreds of threads, a context switch time of 10ms produces a latency in seconds.
Multiple cores
Mutual exclusion solutions fail to take advantage of all of the computing power of a multiple-core system, because only one Thread is allowed inside the Map code at a time. The implementations of the particular concurrent Maps provided by the Java Collections Framework and others sometimes take advantage of multiple cores using Lock free programming techniques. Lock-free techniques use operations like the compareAndSet() intrinsic method available on many of the Java classes such as AtomicReference to do conditional updates of some Map-internal structures atomically. The compareAndSet() primitive is augmented in the JCF classes by native code that can do compareAndSet on special internal parts of some Objects for some algorithms (using 'unsafe' access). The techniques are complex, relying often on the rules of inter-thread communication provided by volatile variables, the happens-before relation, special kinds of lock-free 'retry loops' (which are not like spin locks in that they always produce progress). The compareAndSet() relies on special processor-specific instructions. It is possible for any Java code to use for other purposes the compareAndSet() method on various concurrent classes to achieve Lock-free or even Wait-free concurrency, which provides finite latency. Lock-free techniques are simple in many common cases and with some simple collections like stacks.
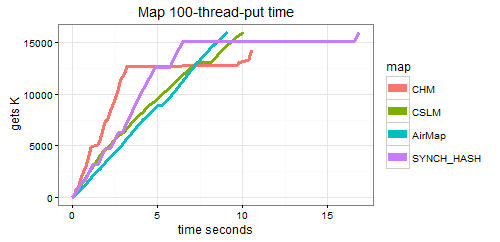
The diagram indicates how synchronizing using Collections.synchronizedMap() wrapping a regular HashMap (purple) may not scale as well as ConcurrentHashMap (red). The others are the ordered ConcurrentNavigableMaps AirConcurrentMap (blue) and ConcurrentSkipListMap (CSLM green). (The flat spots may be rehashes producing tables that are bigger than the Nursery, and ConcurrentHashMap takes more space. Note y axis should say 'puts K'. System is 8-core i7 2.5 GHz, with -Xms5000m to prevent GC). GC and JVM process expansion change the curves considerably, and some internal Lock-Free techniques generate garbage on contention.


Predictable Latency
Yet another problem with mutual exclusion approaches is that the assumption of complete atomicity made by some single-threaded code creates sporadic unacceptably long inter-Thread delays in a concurrent environment. In particular, Iterators and bulk operations like putAll() and others can take a length of time proportional to the Map size, delaying other Threads that expect predictably low latency for non-bulk operations. For example, a multi-threaded web server cannot allow some responses to be delayed by long-running iterations of other threads executing other requests that are searching for a particular value. Related to this is the fact that Threads that lock the Map do not actually have any requirement ever to relinquish the lock, and an infinite loop in the owner Thread may propagate permanent blocking to other Threads. Slow owner Threads can sometimes be Interrupted. Hash-based Maps also are subject to spontaneous delays during rehashing.
Weak consistency
The java.util.concurrency packages' solution to the concurrent modification problem, the convoy problem, the predictable latency problem, and the multi-core problem includes an architectural choice called weak consistency. This choice means that reads like get() will not block even when updates are in progress, and it is allowable even for updates to overlap with themselves and with reads. Weak consistency allows, for example, the contents of a ConcurrentMap to change during an iteration of it by a single Thread. The Iterators are designed to be used by one Thread at a time. So, for example, a Map containing two entries that are inter-dependent may be seen in an inconsistent way by a reader Thread during modification by another Thread. An update that is supposed to change the key of an Entry (k1,v) to an Entry (k2,v) atomically would need to do a remove(k1) and then a put(k2, v), while an iteration might miss the entry or see it in two places. Retrievals return the value for a given key that reflects the latest previous completed update for that key. Thus there is a 'happens-before' relation.
There is no way for ConcurrentMaps to lock the entire table. There is no possibility of ConcurrentModificationException as there is with inadvertent concurrent modification of non-concurrent Maps. The size() method may take a long time, as opposed to the corresponding non-concurrent Maps and other collections which usually include a size field for fast access, because they may need to scan the entire Map in some way. When concurrent modifications are occurring, the results reflect the state of the Map at some time, but not necessarily a single consistent state, hence size(), isEmpty() and containsValue() may be best used only for monitoring.
ConcurrentMap 1.5 Methods
There are some operations provided by ConcurrentMap that are not in Map - which it extends - to allow atomicity of modifications. The replace(K, v1, v2) will test for the existence of v1 in the Entry identified by K and only if found, then the v1 is replaced by v2 atomically. The new replace(k,v) will do a put(k,v) only if k is already in the Map. Also, putIfAbsent(k,v) will do a put(k,v) only if k is not already in the Map, and remove(k, v) will remove the Entry for v only if v is present. This atomicity can be important for some multi-threaded use cases, but is not related to the weak-consistency constraint.
For ConcurrentMaps, the following are atomic.
m.putIfAbsent(k, v) is atomic but equivalent to:
if (k == null || v == null)
throw new NullPointerException();
if (!m.containsKey(k)) {
return m.put(k, v);
} else {
return m.get(k);
}
m replace(k, v) is atomic but equivalent to:
if (k == null || v == null)
throw new NullPointerException();
if (m.containsKey(k)) {
return m.put(k, v);
} else {
return m.get(k);
}
m.replace(k, v1, v2) is atomic but equivalent to:
if (k == null || v1 == null || v2 == null)
throw new NullPointerException();
if (m.containsKey(k) && Objects.equals(m.get(k), v1)) {
m.put(k, v2);
return true;
} else
return false;
}
m.remove(k, v) is atomic but equivalent to:
// if Map does not support null keys or values (apparently independently)
if (k == null || v == null)
throw new NullPointerException();
if (m.containsKey(k) && Objects.equals(m.get(k), v)) {
m.remove(k);
return true;
} else
return false;
}
ConcurrentMap 1.8 Methods
Because Map and ConcurrentMap are interfaces, new methods cannot be added to them without breaking implementations. However, Java 1.8 added the capability for default interface implementations and it added to the Map interface default implementations of some new methods getOrDefault(Object, V), forEach(BiConsumer), replaceAll(BiFunction), computeIfAbsent(K, Function), computeIfPresent(K, BiFunction), compute(K,BiFunction), and merge(K, V, BiFunction). The default implementations in Map do not guarantee atomicity, but in the ConcurrentMap overriding defaults these use Lock free techniques to achieve atomicity, and existing ConcurrentMap implementations will automatically be atomic. The lock-free techniques may be slower than overrides in the concrete classes, so concrete classes may choose to implement them atomically or not and document the concurrency properties.
Lock-free atomicity
It is possible to use Lock-free techniques with ConcurrentMaps because they include methods of a sufficiently high consensus number, namely infinity, meaning that any number of threads may be coordinated. This example could be implemented with the Java 8 merge() but it shows the overall Lock-free pattern, which is more general. This example is not related to the internals of the ConcurrentMap but to the client code's use of the ConcurrentMap. For example, if we want to multiply a value in the Map by a constant C atomically:
static final long C = 10;
void atomicMultiply(ConcurrentMap<Long, Long> map, Long key) {
for (;;) {
Long oldValue = map.get(key);
// Assuming oldValue is not null. This is the 'payload' operation, and should not have side-effects due to possible re-calculation on conflict
Long newValue = oldValue * C;
if (map.replace(key, oldValue, newValue))
break;
}
}
The putIfAbsent(k, v) is also useful when the entry for the key is allowed to be absent. This example could be implemented with the Java 8 compute() but it shows the overall Lock-free pattern, which is more general. The replace(k,v1,v2) does not accept null parameters, so sometimes a combination of them is necessary. In other words, if v1 is null, then putIfAbsent(k, v2) is invoked, otherwise replace(k,v1,v2) is invoked.
void atomicMultiplyNullable(ConcurrentMap<Long, Long> map, Long key) {
for (;;) {
Long oldValue = map.get(key);
// This is the 'payload' operation, and should not have side-effects due to possible re-calculation on conflict
Long newValue = oldValue == null ? INITIAL_VALUE : oldValue * C;
if (replaceNullable(map, key, oldValue, newValue))
break;
}
}
...
static boolean replaceNullable(ConcurrentMap<Long, Long> map, Long key, Long v1, Long v2) {
return v1 == null ? map.putIfAbsent(key, v2) == null : map.replace(key, v1, v2);
}
History
The Java collections framework was designed and developed primarily by Joshua Bloch, and was introduced in JDK 1.2.[2] The original concurrency classes came from Doug Lea's [3] collection package.
See also
References
- ↑ "Collections.synchronizedMap (Java Platform SE 8 )". Docs.oracle.com. 2016. Retrieved 2016-03-20.
- ↑ "The battle of the container frameworks: which should you use?". JavaWorld. 1999-01-01. Retrieved 2011-01-01.
- ↑ Doug Lea. "Overview of package util.concurrent Release 1.3.4". Retrieved 2011-01-01.
- Goetz, Brian; Joshua Bloch; Joseph Bowbeer; Doug Lea; David Holmes; Tim Peierls (2006). Java Concurrency in Practice. Addison Wesley. ISBN 0-321-34960-1.
- Lea, Doug (1999). Concurrent Programming in Java: Design Principles and Patterns. Addison Wesley. ISBN 0-201-31009-0.
External links
| The Wikibook Java Programming has a page on the topic of: Collections |
- Collections Lessons
- Java 6 Collection Tutorial — By Jakob Jenkov, Kadafi Kamphulusa
- Taming Tiger: The Collections Framework
- 'The Collections Framework' (Oracle Java SE 7 documentation)
- 'The Java Tutorials - Collections' by Josh Bloch
- What Java Collection should I use? — A handy flowchart to simplify selection of collections
- 'Which Java Collection to use?' — by Janeve George