Fingerprint (computing)
In computer science, a fingerprinting algorithm is a procedure that maps an arbitrarily large data item (such as a computer file) to a much shorter bit string, its fingerprint, that uniquely identifies the original data for all practical purposes[1] just as human fingerprints uniquely identify people for practical purposes. This fingerprint may be used for data deduplication purposes.
Fingerprints are typically used to avoid the comparison and transmission of bulky data. For instance, a web browser or proxy server can efficiently check whether a remote file has been modified, by fetching only its fingerprint and comparing it with that of the previously fetched copy.[2][3][4][5][6]
Fingerprint functions may be seen as high-performance hash functions used to uniquely identify substantial blocks of data where cryptographic hash functions may be unnecessary. Audio fingerprint algorithms should not be confused with this type of fingerprint function.
Fingerprint properties
Virtual uniqueness
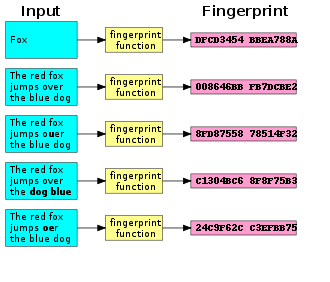
To serve its intended purposes, a fingerprinting algorithm must be able to capture the identity of a file with virtual certainty. In other words, the probability of a collision — two files yielding the same fingerprint — must be negligible, compared to the probability of other unavoidable causes of fatal errors (such as the system being destroyed by war or by a meteorite): say, 10−20 or less.
This requirement is somewhat similar to that of a checksum function, but is much more stringent. To detect accidental data corruption or transmission errors, it is sufficient that the checksums of the original file and any corrupted version will differ with near certainty, given some statistical model for the errors. In typical situations, this goal is easily achieved with 16- or 32-bit checksums. In contrast, file fingerprints need to be at least 64-bit long to guarantee virtual uniqueness in large file systems (see birthday attack).
When proving the above requirement, one must take into account that files are generated by highly non-random processes that create complicated dependencies among files. For instance, in a typical business network, one usually finds many pairs or clusters of documents that differ only by minor edits or other slight modifications. A good fingerprinting algorithm must ensure that such "natural" processes generate distinct fingerprints, with the desired level of certainty.
Compounding
Computer files are often combined in various ways, such as concatenation (as in archive files) or symbolic inclusion (as with the C preprocessor's #include directive). Some fingerprinting algorithms allow the fingerprint of a composite file to be computed from the fingerprints of its constituent parts. This "compounding" property may be useful in some applications, such as detecting when a program needs to be recompiled.
Fingerprinting algorithms
Rabin's algorithm
Rabin's fingerprinting algorithm [7] is the prototype of the class. It is fast and easy to implement, allows compounding, and comes with a mathematically precise analysis of the probability of collision. Namely, the probability of two strings r and s yielding the same w-bit fingerprint does not exceed max(|r|,|s|)/2w-1, where |r| denotes the length of r in bits. The algorithm requires the previous choice of a w-bit internal "key", and this guarantee holds as long as the strings r and s are chosen without knowledge of the key.
Rabin's method is not secure against malicious attacks. An adversarial agent can easily discover the key and use it to modify files without changing their fingerprint.
Cryptographic hash functions
Mainstream cryptographic grade hash functions generally can serve as high-quality fingerprint functions, are subject to intense scrutiny from cryptanalysts, and have the advantage that they are believed to be safe against malicious attacks.
A drawback of cryptographic hash algorithms such as MD5 and SHA is that they take considerably longer to execute than Rabin's fingerprint algorithm. They also lack proven guarantees on the collision probability. Some of these algorithms, notably MD5, are no longer recommended for secure fingerprinting. They are still useful for error checking, where purposeful data tampering isn't a primary concern.
Fingerprinting and Watermarking for Relational Databases
Fingerprinting and digital watermarking for relational databases emerged as candidate solutions to provide copyright protection, tamper detection, traitor tracing, and maintaining integrity of relational data. Many techniques have been proposed in the literature to address these purposes. A survey of the current state-of-the-art and a classification of the different approaches according to their intent, the way they express the fingerprint/watermark, the cover type, the granularity level, and their verifiability, is available.[8]
Application examples
NIST distributes a software reference library, the American National Software Reference Library, that uses cryptographic hash functions to fingerprint files and map them to software products. The HashKeeper database, maintained by the National Drug Intelligence Center, is a repository of fingerprints of "known to be good" and "known to be bad" computer files, for use in law enforcement applications (e.g. analyzing the contents of seized disk drives).
See also
- Acoustic fingerprinting
- Digital video fingerprinting
- TCP/IP stack fingerprinting
- Device fingerprint
- Error correcting code
- Public key fingerprint
- Randomizing function
References
- ↑ A. Z. Broder. Some applications of Rabin's fingerprinting method. In Sequences II: Methods in Communications, Security, and Computer Science, pages 143--152. Springer-Verlag, 1993
- ↑ Detecting duplicate and near-duplicate files. US Patent 6658423 Issued on December 2, 2003
- ↑ A. Z. Broder, "On the Resemblance and Containment of Documents," Proceedings of Compression and Complexity of Sequences 1997, pp. 21-27, IEEE Computer Society (1988)
- ↑ S. Brin et al., "Copy Detection Mechanisms for Digital Documents," Proceedings of the ACM SIGMOD Annual Conference, San Jose 1995 (May 1995)
- ↑ L. Fan, P. Cao, J. Almeida and A. Broder, Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol, IEEE/ACM Transactions on Networking, vol. 8, No. 3 (2000)
- ↑ U. Manber, Finding Similar Files in a Large File System. Proceedings of the USENIX Winter Technical Conf. (1994)
- ↑ M. O. Rabin Fingerprinting by random polynomials. Center for Research in Computing Technology Harvard University Report TR-15-81 (1981)
- ↑ http://www.jucs.org/jucs_16_21/watermarking_techniques_for_relational/jucs_16_21_3164_3190_halder.pdf