Dotted and dotless I
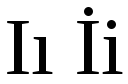
The Turkish alphabet, which is a variant of the Latin alphabet, includes two distinct versions of the letter I, one dotted and the other dotless.
The dotless I, I ı, denotes the close back unrounded vowel sound (/ɯ/). Neither the upper nor the lower case version has a dot.
The dotted İ, İ i, denotes the close front unrounded vowel sound (/i/). Both the upper and lower case versions have a dot.
Examples:
- İstanbul /isˈtanbuɫ/ (starts with an i sound, not an ı).
- Diyarbakır /dijaɾˈbakɯɾ/ (the first and last vowels are spelled and pronounced differently)
In contrast, the letter j does not have this distinction, with a dot only on the lower case character: J j.
In scholarly writing on Turkic languages, ï is sometimes used for /ɯ/.[1]
Consequence for ligatures

In some fonts, if the lowercase letters fi are placed adjacently, the dot-like upper end of the f would fall inconveniently close to the dot of the i, and therefore a ligature glyph is provided with the top of the f extended to serve as the dot of the i. A similar ligature for ffi is also possible. Since the unligatured forms are unattractive and the ligatures make the i dotless, such fonts are not appropriate for use in a Turkish setting. However, the fi ligatures of some fonts do not merge the letters and instead space them next to each other, with the dot on the i remaining. Such fonts are appropriate for Turkish, but the writer must be careful to be consistent in the use of ligatures.
In computing
| Character | I | i | İ | ı | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | LATIN CAPITAL LETTER I | LATIN SMALL LETTER I | LATIN CAPITAL LETTER I WITH DOT ABOVE | LATIN SMALL LETTER DOTLESS I | ||||
| Encodings | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 73 | U+0049 | 105 | U+0069 | 304 | U+0130 | 305 | U+0131 |
| UTF-8 | 73 | 49 | 105 | 69 | 196 176 | C4 B0 | 196 177 | C4 B1 |
| Numeric character reference | I | I | i | i | İ | İ | ı | ı |
| ISO 8859-9 | 73 | 49 | 105 | 69 | 221 | DD | 253 | FD |
| ISO 8859-3 | 73 | 49 | 105 | 69 | 169 | A9 | 185 | B9 |
In normal typography, when lower case i is combined with other diacritics, the dot is generally removed before the diacritic is added; however, Unicode still lists the equivalent combining sequences as including the dotted i, since logically it is the normal dotted i character that is being modified.
Most Unicode software uppercases ı to I and lowercases İ to i, but, unless specifically set up for Turkish, it lowercases I to i and uppercases i to I. Thus uppercasing then lowercasing, or vice versa, changes the letters.
In the Microsoft Windows SDK, beginning with Windows Vista, several relevant functions have a NORM_LINGUISTIC_CASING flag, to indicate that for Turkish and Azerbaijani locales, I should map to ı and i to İ.
In the LaTeX typesetting language the dotless ı can be written with the backslash-i command: \i. The İ can be written using the normal accenting method (i.e. \.{I}).
Dotless ı (and dotted capital İ) is handled problematically in the Turkish locales of several software packages, including Oracle DBMS, PHP, Java (software platform),[2][3] and Unixware 7, where implicit capitalization of names of keywords, variables, and tables has effects not foreseen by the application developers. The C or US English locales do not have these problems. The .NET Framework has special provisions to handle the 'Turkish i'.[4]
Many cellphones available in Turkey (as of 2008) lack a proper localization, which leads to replacing ı by i in SMS, sometimes severely distorting the sense of a text. In one instance, a miscommunication played a role in the deaths of Emine and Ramazan Çalçoban in 2008.[5][6] A common substitution is to use the character 1 for dotless ı.
Implications for casing
The casing of the dotless and dotted ı forms differ from other languages. That implies that a case insensitive matching expected by an English person doesn't match the expectations of a Turkish user. The "Turkish I" is often used as an example of the problems with case insensitivity in computing.
Usage in other languages
Dotted and dotless i are used in several other writing systems for Turkic languages:
- Azerbaijani: The Azerbaijani Latin alphabet used in Azerbaijan is modeled after Turkish since 1991.
- Kazakh: The Kazakh alphabet as used in Kazakhstan is Cyrillic; however, several Romanization schemes exist. Dotted and dotless I, in addition to I with diaraesis (Ï ï) are employed in the Latin script versions of the Kazakh Wikipedia and of several governmental websites. The main website of the government of Kazakhstan[7] and the national information agency KazInform-QazAqparat[8] offer Turkish-like Latin script along with official Cyrillic one.
- Tatar: The Tatar alphabet in Russia is officially Cyrillic due to the requirements of Russian federal law. Several Romanization schemes exist, which are used on the Internet and some printed publication. Most of them are modelled in different ways on Turkish and employ dotted and dotless I, while some also use I with acute (Í), although for different phonemes. The only Latin alphabet that ever had official status in Tatarstan, Yañalif, used the character Ь instead of dotless i.
- Crimean Tatar: The Latin alphabet is officially used for the Crimean Tatar language and does use both dotted and dotless I letters. Cyrillic script is still used in daily life in the Autonomous Republic of Crimea, but is not the official script for the language.
The dotless ı may also be used as a stylistic variant of the dotted i, without there being any meaningful difference between them. This is common in Irish, for example. See Tittle.
Both the dotted and dotless I can be used in transcriptions of Rusyn to allow distinguishing between the letters ы and и, which would otherwise be both transcripted as "y", despite representing different phonemes. Under such transcription the Dotted İ would represent the cyrillic і, and the dotless I would represent either ы or и, with the other being represented by "y".
See also
- Tittle: the dot above "i" and "j" in most of the Latin scripts
- Yery (ы) — a letter used to represent [ɯ] in Turkic languages with Cyrillic script, and the similar [ɨ] in Russian.
Notes
- ↑ Marcel Erdal, A Grammar of Old Turkic, Handbook of Oriental Studies 3, ISBN 9004102949, 2004, p. 52
- ↑ Turkish Java needs special brewing
- ↑ The Policeman’s Horror: Default Locales, Default Charsets, and Default Timezones
- ↑ MSDN: Writing Culture-Safe Managed Code: The Turkish Example
- ↑ Diaz, Jesus (2008-04-21). "A cellphone's missing dot kills two people, puts three more in jail". Gizmodo. Retrieved 2015-08-28.
- ↑ Orion, Egan (2008-04-26). "Cellphone localisation glitch turned deadly in Turkey – dotted i leads to tragedy]". The Inquirer. Retrieved 2015-08-28.
- ↑ Government of Kazakhstan (Kazakh Cyrillic/Latin)
- ↑ KazInform (Kazakh Cyrillic/Latin)
References
- http://www.unicode.org/charts/PDF/U0100.pdf
- Tex Texin, Internationalization for Turkish: Dotted and Dotless Letter "I", accessed 15 Nov 2005