Beta-binomial distribution
|
Probability mass function
| |
|
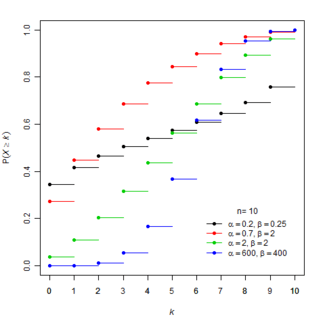
Cumulative distribution function
| |
| Parameters |
n ∈ N0 — number of trials (real) (real) |
|---|---|
| Support | k ∈ { 0, …, n } |
| pmf | |
| CDF |
where 3F2(a,b,k) is the generalized hypergeometric function =3F2(1, α + k + 1, −n + k + 1; k + 2, −β − n + k + 2; 1) |
| Mean | |
| Variance | |
| Skewness | |
| Ex. kurtosis | See text |
| MGF |
|
| CF |
|












In probability theory and statistics, the beta-binomial distribution is a family of discrete probability distributions on a finite support of non-negative integers arising when the probability of success in each of a fixed or known number of Bernoulli trials is either unknown or random. The beta-binomial distribution is the binomial distribution in which the probability of success at each trial is not fixed but random and follows the beta distribution. It is frequently used in Bayesian statistics, empirical Bayes methods and classical statistics to capture overdispersion in binomial type distributed data.
It reduces to the Bernoulli distribution as a special case when n = 1. For α = β = 1, it is the discrete uniform distribution from 0 to n. It also approximates the binomial distribution arbitrarily well for large α and β. The beta-binomial is a one-dimensional version of the Dirichlet-multinomial distribution, as the binomial and beta distributions are univariate versions of the multinomial and Dirichlet distributions, respectively.
Motivation and derivation
Beta-binomial distribution as a compound distribution
The Beta distribution is a conjugate distribution of the binomial distribution. This fact leads to an analytically tractable compound distribution where one can think of the parameter in the binomial distribution as being randomly drawn from a beta distribution. Namely, if


then

where Bin(n,p) stands for the binomial distribution, and where p is a random variable with a beta distribution.

then the compound distribution is given by

Using the properties of the beta function, this can alternatively be written

Beta-binomial as an urn model
The beta-binomial distribution can also be motivated via an urn model for positive integer values of α and β, known as the Polya urn model. Specifically, imagine an urn containing α red balls and β black balls, where random draws are made. If a red ball is observed, then two red balls are returned to the urn. Likewise, if a black ball is drawn, then two black balls are returned to the urn. If this is repeated n times, then the probability of observing k red balls follows a beta-binomial distribution with parameters n,α and β.
Note that if the random draws are with simple replacement (no balls over and above the observed ball are added to the urn), then the distribution follows a binomial distribution and if the random draws are made without replacement, the distribution follows a hypergeometric distribution.
Moments and properties
The first three raw moments are
![{\begin{aligned}\mu _{1}&={\frac {n\alpha }{\alpha +\beta }}\\[8pt]\mu _{2}&={\frac {n\alpha [n(1+\alpha )+\beta ]}{(\alpha +\beta )(1+\alpha +\beta )}}\\[8pt]\mu _{3}&={\frac {n\alpha [n^{{2}}(1+\alpha )(2+\alpha )+3n(1+\alpha )\beta +\beta (\beta -\alpha )]}{(\alpha +\beta )(1+\alpha +\beta )(2+\alpha +\beta )}}\end{aligned}}](../I/m/d8b08123d7cc1c1b79069bd5d3d3f78776de5945.svg)
and the kurtosis is
![\beta_2 = \frac{(\alpha + \beta)^2 (1+\alpha+\beta)}{n \alpha \beta( \alpha + \beta + 2)(\alpha + \beta + 3)(\alpha + \beta + n) } \left[ (\alpha + \beta)(\alpha + \beta - 1 + 6n) + 3 \alpha\beta(n - 2) + 6n^2 -\frac{3\alpha\beta n(6-n)}{\alpha + \beta} - \frac{18\alpha\beta n^{2}}{(\alpha+\beta)^2} \right].](../I/m/8a0a324a1e2fa8215447cc6cf5761738050f371f.svg)
Letting we note, suggestively, that the mean can be written as


and the variance as
![\sigma ^{2}={\frac {n\alpha \beta (\alpha +\beta +n)}{(\alpha +\beta )^{2}(\alpha +\beta +1)}}=n\pi (1-\pi ){\frac {\alpha +\beta +n}{\alpha +\beta +1}}=n\pi (1-\pi )[1+(n-1)\rho ]\!](../I/m/991ce686abc74a57c81097ad07c2b8eca60b5178.svg)
where . The parameter is known as the "intra class" or "intra cluster" correlation. It is this positive correlation which gives rise to overdispersion.


The following recurrence relation holds:
![\left\{\begin{array}{l}
(\alpha +k) (n-k) p(k)-(k+1) p(k+1) (\beta-k+n-1)=0, \\[10pt]
p(0)=\frac{(\beta)_n}{(\alpha +\beta)_n}
\end{array}\right\}](../I/m/8702f2fae8d9521b9b059c52ad983cf516a5a343.svg)
Point estimates
Method of moments
The method of moments estimates can be gained by noting the first and second moments of the beta-binomial namely
![{\begin{aligned}\mu _{1}&={\frac {n\alpha }{\alpha +\beta }}\\\mu _{2}&={\frac {n\alpha [n(1+\alpha )+\beta ]}{(\alpha +\beta )(1+\alpha +\beta )}}\end{aligned}}](../I/m/0335fa7b026924ba0f376817b47e4cc027a66ee5.svg)
and setting these raw moments equal to the first and second raw sample moments respectively

and solving for α and β we get

Note that these estimates can be non-sensically negative which is evidence that the data is either undispersed or underdispersed relative to the binomial distribution. In this case, the binomial distribution and the hypergeometric distribution are alternative candidates respectively.
Maximum likelihood estimation
While closed-form maximum likelihood estimates are impractical, given that the pdf consists of common functions (gamma function and/or Beta functions), they can be easily found via direct numerical optimization. Maximum likelihood estimates from empirical data can be computed using general methods for fitting multinomial Pólya distributions, methods for which are described in (Minka 2003). The R package VGAM through the function vglm, via maximum likelihood, facilitates the fitting of glm type models with responses distributed according to the beta-binomial distribution. Note also that there is no requirement that n is fixed throughout the observations.
Example
The following data gives the number of male children among the first 12 children of family size 13 in 6115 families taken from hospital records in 19th century Saxony (Sokal and Rohlf, p. 59 from Lindsey). The 13th child is ignored to assuage the effect of families non-randomly stopping when a desired gender is reached.
| Males | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Families | 3 | 24 | 104 | 286 | 670 | 1033 | 1343 | 1112 | 829 | 478 | 181 | 45 | 7 |
We note the first two sample moments are

and therefore the method of moments estimates are

The maximum likelihood estimates can be found numerically

and the maximized log-likelihood is

from which we find the AIC

The AIC for the competing binomial model is AIC = 25070.34 and thus we see that the beta-binomial model provides a superior fit to the data i.e. there is evidence for overdispersion. Trivers and Willard posit a theoretical justification for heterogeneity (also known as "burstiness") in gender-proneness among mammalian offspring (i.e. overdispersion).
The superior fit is evident especially among the tails
| Males | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Observed Families | 3 | 24 | 104 | 286 | 670 | 1033 | 1343 | 1112 | 829 | 478 | 181 | 45 | 7 |
| Fitted Expected (Beta-Binomial) | 2.3 | 22.6 | 104.8 | 310.9 | 655.7 | 1036.2 | 1257.9 | 1182.1 | 853.6 | 461.9 | 177.9 | 43.8 | 5.2 |
| Fitted Expected (Binomial p = 0.519215) | 0.9 | 12.1 | 71.8 | 258.5 | 628.1 | 1085.2 | 1367.3 | 1265.6 | 854.2 | 410.0 | 132.8 | 26.1 | 2.3 |
Further Bayesian considerations
It is convenient to reparameterize the distributions so that the expected mean of the prior is a single parameter: Let

where

so that

The posterior distribution ρ(θ|k) is also a beta distribution:

And

while the marginal distribution m(k|μ, M) is given by

Substituting back M and μ, in terms of and , this becomes:



which is the expected beta-binomial distribution with parameters and .

We can also use the method of iterated expectations to find the expected value of the marginal moments. Let us write our model as a two-stage compound sampling model. Let ki be the number of success out of ni trials for event i:

We can find iterated moment estimates for the mean and variance using the moments for the distributions in the two-stage model:
![\operatorname {E}\left({\frac {k}{n}}\right)=\operatorname {E}\left[\operatorname {E}\left(\left.{\frac {k}{n}}\right|\theta \right)\right]=\operatorname {E}(\theta )=\mu](../I/m/9a111b29de189969aa34cc5790268d6bf7b03c49.svg)
![{\begin{aligned}\operatorname {var}\left({\frac {k}{n}}\right)&=\operatorname {E}\left[\operatorname {var}\left(\left.{\frac {k}{n}}\right|\theta \right)\right]+\operatorname {var}\left[\operatorname {E}\left(\left.{\frac {k}{n}}\right|\theta \right)\right]\\&=\operatorname {E}\left[\left(\left.{\frac {1}{n}}\right)\theta (1-\theta )\right|\mu ,M\right]+\operatorname {var}\left(\theta |\mu ,M\right)\\&={\frac {1}{n}}\left(\mu (1-\mu )\right)+{\frac {n-1}{n}}{\frac {(\mu (1-\mu ))}{M+1}}\\&={\frac {\mu (1-\mu )}{n}}\left(1+{\frac {n-1}{M+1}}\right).\end{aligned}}](../I/m/438baab1daf413e73ad505c669a36bfa51e45ed2.svg)
(Here we have used the law of total expectation and the law of total variance.)
We want point estimates for and . The estimated mean is calculated from the sample




The estimate of the hyperparameter M is obtained using the moment estimates for the variance of the two-stage model:
![s^{2}={\frac {1}{N}}\sum _{{i=1}}^{N}\operatorname {var}\left({\frac {k_{{i}}}{n_{{i}}}}\right)={\frac {1}{N}}\sum _{{i=1}}^{N}{\frac {{\hat {\mu }}(1-{\hat {\mu }})}{n_{i}}}\left[1+{\frac {n_{i}-1}{\widehat {M}+1}}\right]](../I/m/19386d20df15dc6be26153f8e39ffbc36c815a6a.svg)
Solving:

where

Since we now have parameter point estimates, and , for the underlying distribution, we would like to find a point estimate for the probability of success for event i. This is the weighted average of the event estimate and . Given our point estimates for the prior, we may now plug in these values to find a point estimate for the posterior




Shrinkage factors
We may write the posterior estimate as a weighted average:

where is called the shrinkage factor.


Related distributions
- where is the discrete uniform distribution.


See also
References
- Minka, Thomas P. (2003). Estimating a Dirichlet distribution. Microsoft Technical Report.
External links
- Using the Beta-binomial distribution to assess performance of a biometric identification device
- Fastfit contains Matlab code for fitting Beta-Binomial distributions (in the form of two-dimensional Pólya distributions) to data.
- Interactive graphic: Univariate Distribution Relationships
- Beta-binomial functions in VGAM R package
- Beta-binomial distribution in Sandia National Labs Cognitive Foundry Java library